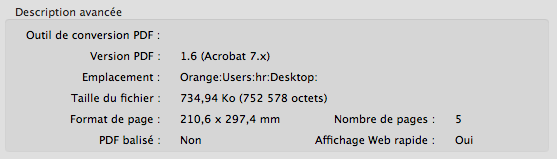
je suis perplexe.
J’ai reçu par mail un PDF contenant une page imprimée, annotée à la main puis scannée et convertie en PDF.
Aucun doute, c’est bien l’image d’une feuille de papier scannée incluse dans un PDF comme le montrent les petites taches par-ci par-là et de nombreuses annotations au crayon. Le contenu est aussi très légèrement de travers.
Moi, bêtement, par automatisme, je sélectionne une ligne, pomme-C puis pomme-V dans un document et c’est bon, j’ai ma copie de ligne. Et c’est là que je me rends compte de ce que j’ai fait…

J’ai copié l’image d’un texte et j’ai eu le texte, comme si Aperçu faisait de la reconnaissance de caractère… La sélection s’est faite avec le pointeur de souris comme lors de la sélection dans un traitement de texte ce que j’aurais déjà dû trouver louche.
J’ai fait un essai avec deux nombres 450 qui étaient légèrement biffés d’un coup de crayon : j’ai pu copier mais j’ai obtenu §O-l)Ef sur un échantillon et 45O-i)O le trait de crayon étant plus costaud sur le premier et léger sur le second. Ce qui veut dire que c’est bien Aperçu qui a reconnu qu’il s’agissait de caractères, cette fois en se trompant mais ce n’est pas si mal pour un nombre barré. Le texte n’est donc pas inclus dans le PDF sous forme de texte et la ligne que j’ai recopiée a forcément dû être reconnue, et parfaitement en plus puisqu’elle était propre, sans trace de crayon, dans l’image.
J’ai essayé de faire le même coup dans d’autres documents images mais ça ne donne rien. J’ai converti ces images en PDF, rien. Ça dépend peut-être de la police, je ne sais pas. Ou de la qualité du scannage ? Les autres n’avaient pas l’air mal pourtant.
Rien trouvé dans l’aide d’Aperçu.
Ça vous paraît normal ? C’est effectivement une fonction incluse dans Aperçu ?
_______________
J’étais né pour rester jeune et j’ai eu l'avantage de m’en apercevoir le jour où j’ai cessé de l'être.
Épitaphe de Georges Moinaux, dit Courteline